Current Projects
My work aims to improve the performance, efficiency, predictability, and ease of use of cloud systems, in light of emerging hardware (increased heterogeneity) and software (microservices and serverless) trends. To this end, in my group we are exploring the following research directions that span the cloud system stack.
Hardware Specialization and Server Design for the Cloud
We are working to redesign cloud hardware, both using hardware acceleration and alternative platform designs, which address the challenges emerging cloud programming models, like microservices, introduce. First, microservices drastically change the cloud resource bottlenecks. While previously the majority of the end-to-end latency went towards useful computation, now a large fraction (if not the majority) of latency goes towards processing network requests. A small amount of unpredictability in the network stack, e.g., due to queueing, can significantly degrade the end-to-end Quality-of-Service (QoS).
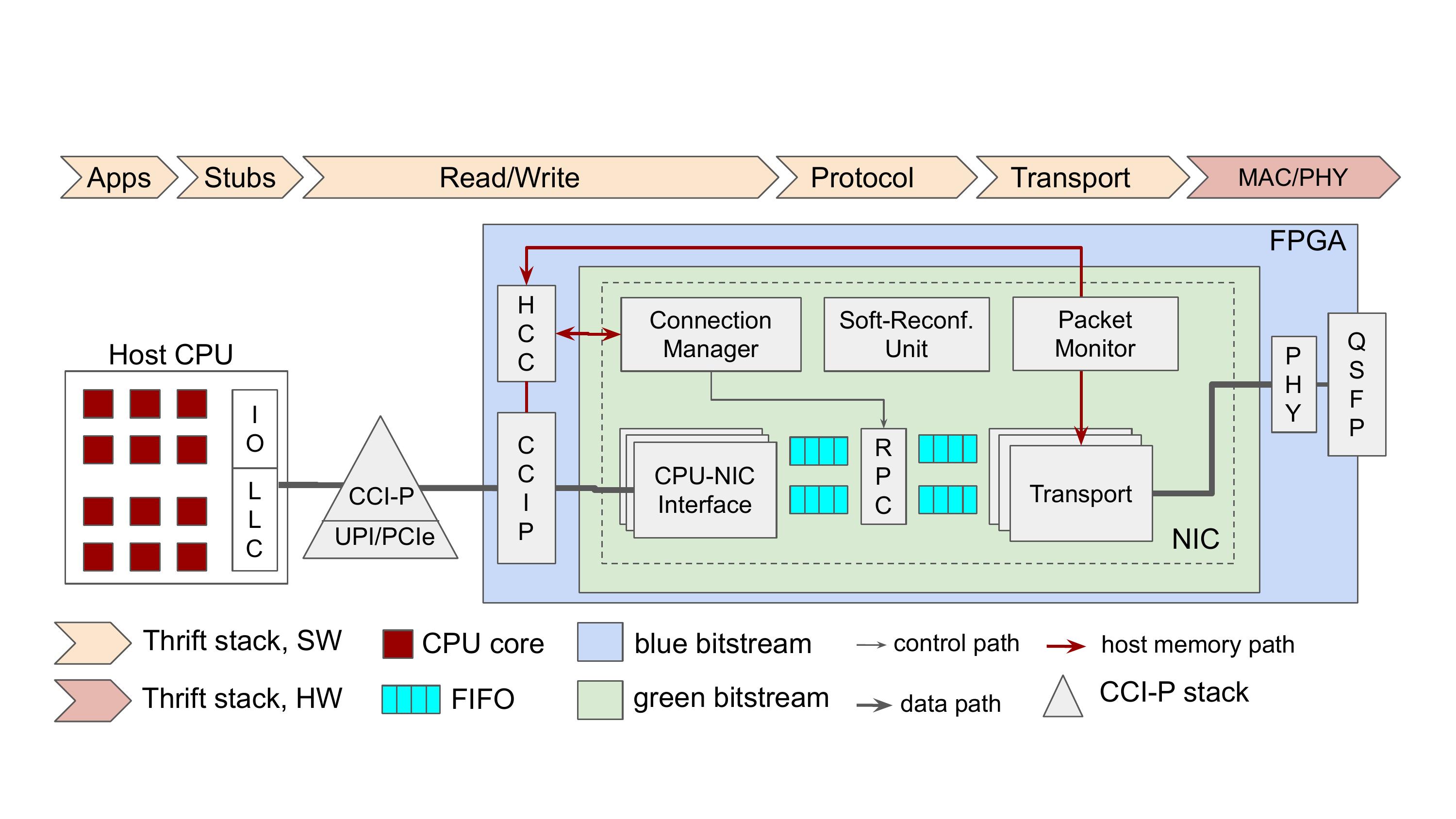
In this line of work, we quantified the value hardware acceleration has in alleviating these overheads. We designed Dagger, an FPGA-based acceleration fabric for Remote Procedure Call (RPC) processing. Dagger offloads the entire networking stack to hardware, uses an FPGA tightly coupled to the main CPU, and makes the network interface reconfigurable, to adjust to the diverse needs of microservices. Dagger achieves 1.3-3.8x higher per-core RPC throughput over prior hardware and software solutions, while also improving tail latency. It also allows easily porting complex applications with minimal changes to their codebase. While we designed Dagger for microservices, it also benefits traditional cloud applications, like databases, key-value stores, and webservers.
Beyond FPGA-based acceleration, we have also explored DRAM-based computation, as well as how recent hardware trends, like low-power cores, and Processing-in-Memory (PIM) benefit the performance of interactive cloud services, and designed a QoS- aware scheduler that manages the heterogeneous resources that PIM introduces.
Machine-Learning-Driven Cloud Management
The emergence of microservices introduces new cluster management challenges, which previous cluster managers do not address. Specifically, the dependencies between microservices introduce backpressure effects, which can lead to system-wide cascading hotspots. Existing cluster managers view different cloud applications as independent from each other, overlooking the impact dependencies between service tiers have.
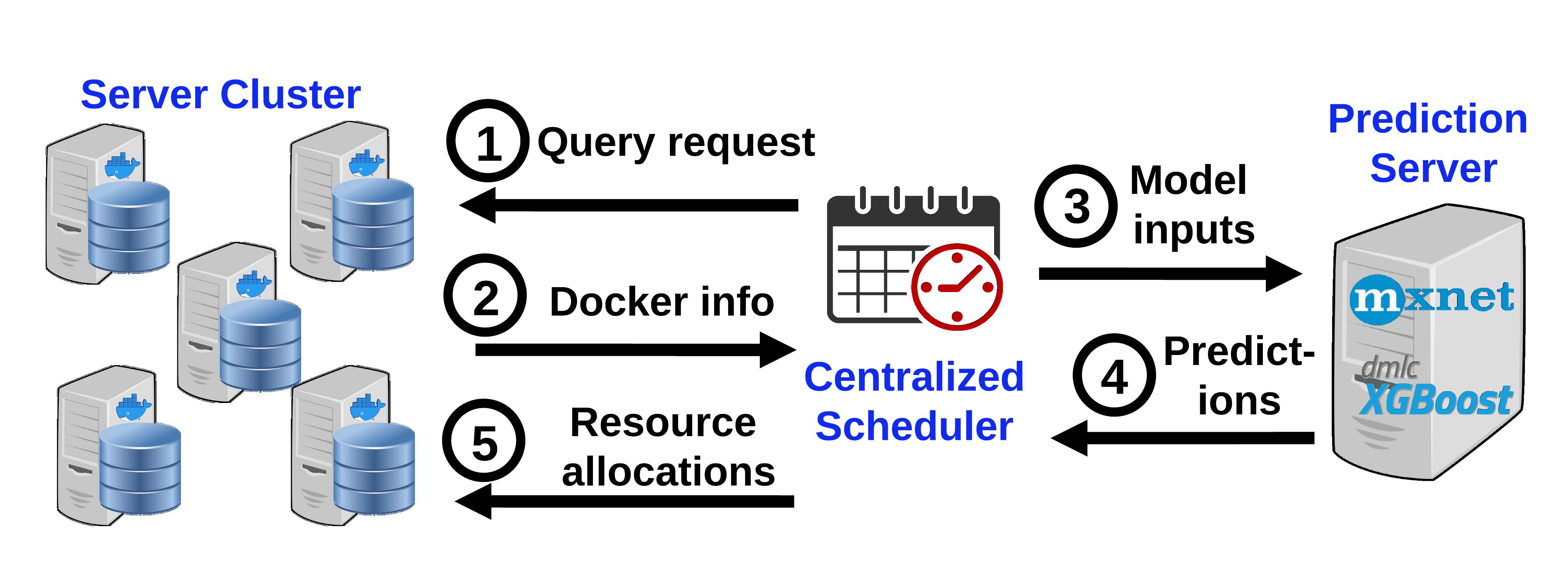
We have developed two approaches for cluster management in microservices.
First, we built Sinan, an ML-driven cluster manager that leverages a set of validated ML models to infer the impact of dependencies between microservices, taking into account that they are too complex for users to describe or even understand. Sinan arrives at a resource allocation for each microservice that meets the end-to-end QoS target without overprovisioning. Sinan infers both the immediate impact of a resource allocation and the long-term performance evolution, %uses a Convolutional Neural Network to infer the impact of a resource allocation in the near-future, and a faster Boosted Trees method to evaluate how performance will evolve in the long term, accounting for the system’s inertia in building up queues. We have shown that not only does Sinan meet QoS at high utilization, but its output is interpretable, giving system designers actionable feedback on design and management decisions that are likely to cause performance issues.
Beyond this ML-driven approach, we have also explored techniques that rely on queueing network principles to identify microservice dependencies prone to performance issues, and allocate resources accordingly. The resulting system, Cloverleaf, uses flow control in queueing networks to decouple dependent microservices, and identify the per-microservice QoS targets that, when met, guarantee the end-to-end QoS. This reduces the problem of managing a graph of dependent services to managing $N$ independent tiers, allowing simpler, per-node resource managers to be applied.
To this end, we have developed PARTIES, a resource controller that partitions and isolates resources among multiple latency-critical applications running on a physical node. PARTIES uses hardware and OS isolation mechanisms to partition cores, memory, cache, network, storage, and power resources. PARTIES is based on a simple feedback loop, and requires no a priori information about each microservice beyond its QoS target, using instead the insight that resources are fungible, i.e., one resource can be traded off for another to reach fast allocation decisions.
We have also explored finer-grained resource allocations, at the individual request level, showing that unlike in prior work, simple linear models are sufficient to achieve power management that is both QoS-aware and resource efficient.
Machine-Learning-Driven Cloud Performance Debugging
Performance unpredictability is especially impactful in microservices, as it does not only harm the service that experiences it, but can also introduce domino effects across dependent microservices. These issues are hard to detect and even harder to recover from. As such, retroactive performance debugging techniques, which only take action after observing a performance issue, lead to poor performance and/or inefficiency.
In recent work we demonstrated that a data-driven approach is especially effective in performance debugging, because it leverages the massive amounts of tracing data collected in cloud systems to identify patterns signaling upcoming performance issues. We have proposed two approaches, one based on supervised learning, and one on unsupervised learning.
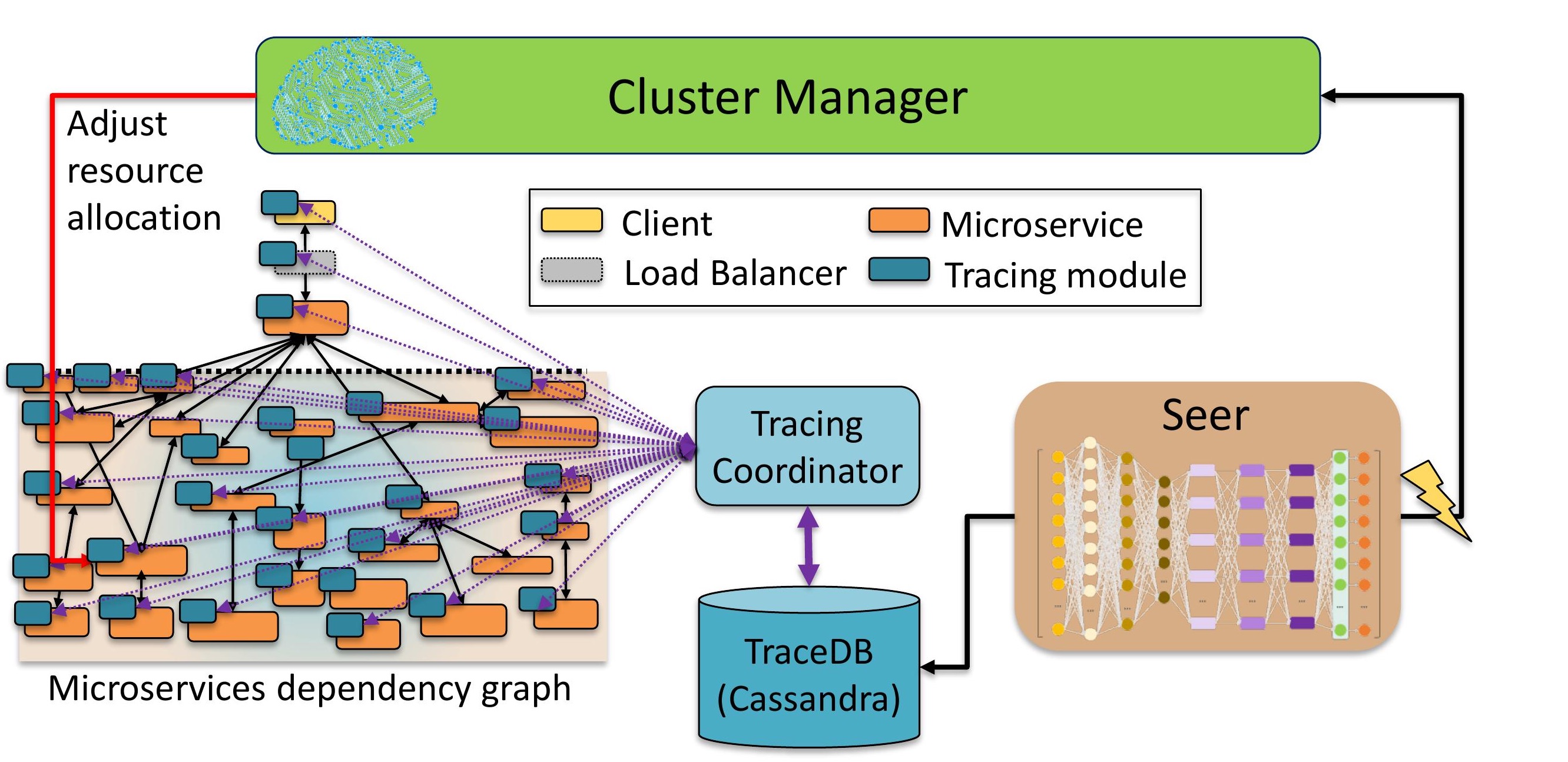
Seer, is an online performance debugging and root cause analysis system that uses deep learning to identify patterns in space and time that signal upcoming QoS violations, and pinpoint their root causes. By identifying such issues early, Seer takes proactive action and avoids the performance issue altogether. We have validated Seer across end-to-end applications built with microservices and shown that it correctly identifies over 92% of QoS violations and avoids 87% of them.
While Seer is accurate, it has some limitations that make its deployment in production challenging. First, since it relies on supervised learning, it requires training on traces annotated with the root causes of QoS violations. To obtain these, QoS violations need to be %ensure correct annotation QoS violations are induced by creating resource contention, which is problematic in production. Similarly, Seer requires high-frequency trace collection and kernel instrumentation, which are not always available in clouds hosting third-party applications.
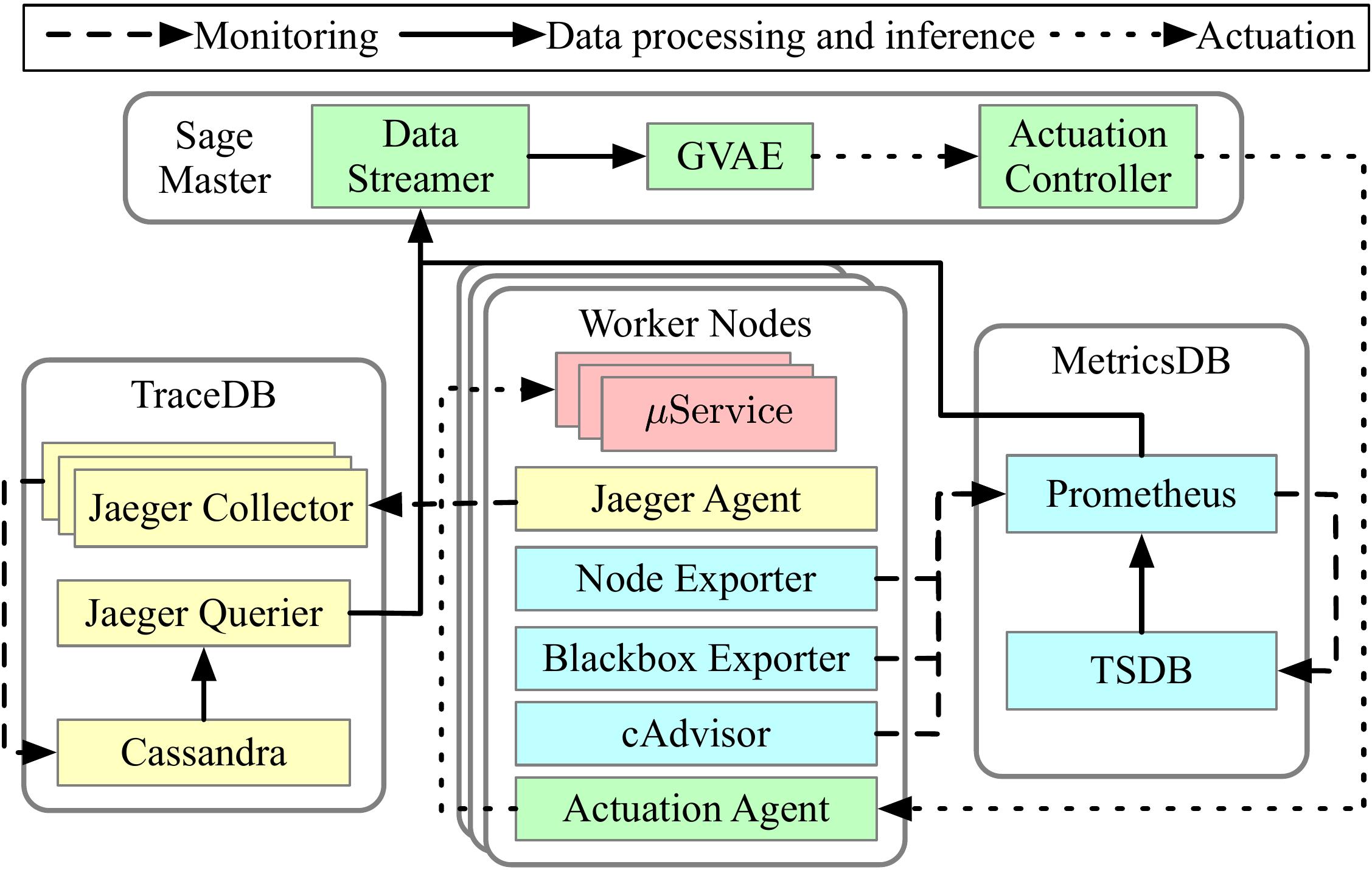
To address these issues, we designed Sage, in collaboration with Google, which relies entirely on unsupervised learning for root cause analysis. Sage automatically builds the graph of dependencies between microservices using a Causal Bayesian Network (CBN) and explores scenarios that can solve a performance issue through a generative Graphical Variational AutoEncoder (GVAE). Sage achieves the same accuracy as supervised learning while being much more practical and scalable. It also easily accommodates changes to the application’s design and deployment, which are frequent in microservices, by employing partial and incremental retraining.
In addition, Sage’s output is explainable, providing useful insights to both cloud providers and application designers on patterns that are prone to performance issues and/or resource inefficiency. In a cluster deployment of a Social Network application at Cornell, driven by real user traffic, Sage was able to identify design bugs responsible for performance issues, and assist the application developers to pinpoint and correct them. As cloud systems become more complex, ML-driven systems like Seer and Sage offer practical solutions where previous empirical approaches become ineffective.
Cloud Programming Framework Design
In addition to microservices, serverless frameworks have also gained in popularity. While a similar concept to microservices, serverless takes advantage of fine-grained parallelism and intermittent activity in applications to spawn a large number of concurrent instances, improve performance, reduce overprovisioning, and simplify cloud maintenance. At the same time, serverless is prone to poor performance due to data transfers, instantiation overheads, and contention due to multi-tenancy.
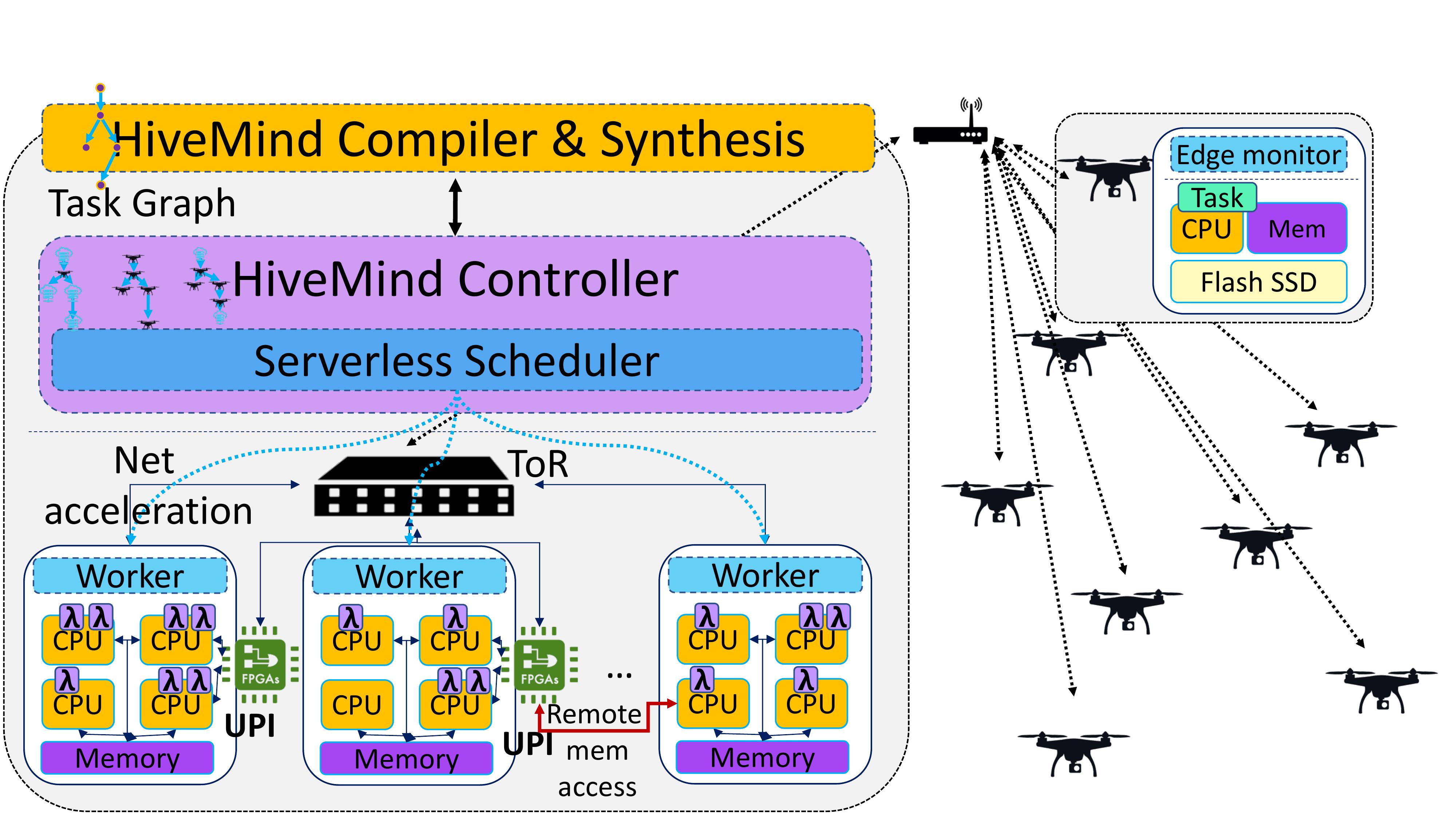
In recent work we have developed several solutions for serverless, including implementing an FPGA-based RDMA accelerator to facilitate—in a secure way—data transfers between dependent serverless tasks, and designing a QoS-aware scheduler for serverless workflows with multiple stages that determines when tasks should be instantiated, where, and with how many resources. We have also developed Ripple, a programming framework that converts traditional cloud applications to serverless workflows, and designed a management framework, in collaboration with Microsoft Research, that harvests unallocated resources to accommodate serverless functions without hurting performance. Finally, we have also demonstrated the value of serverless for cloud-edge systems, and designed HiveMind, an end-to-end hardware-software stack for IoT swarms that leverages serverless to offload computation to a hardware-accelerated backend cloud.
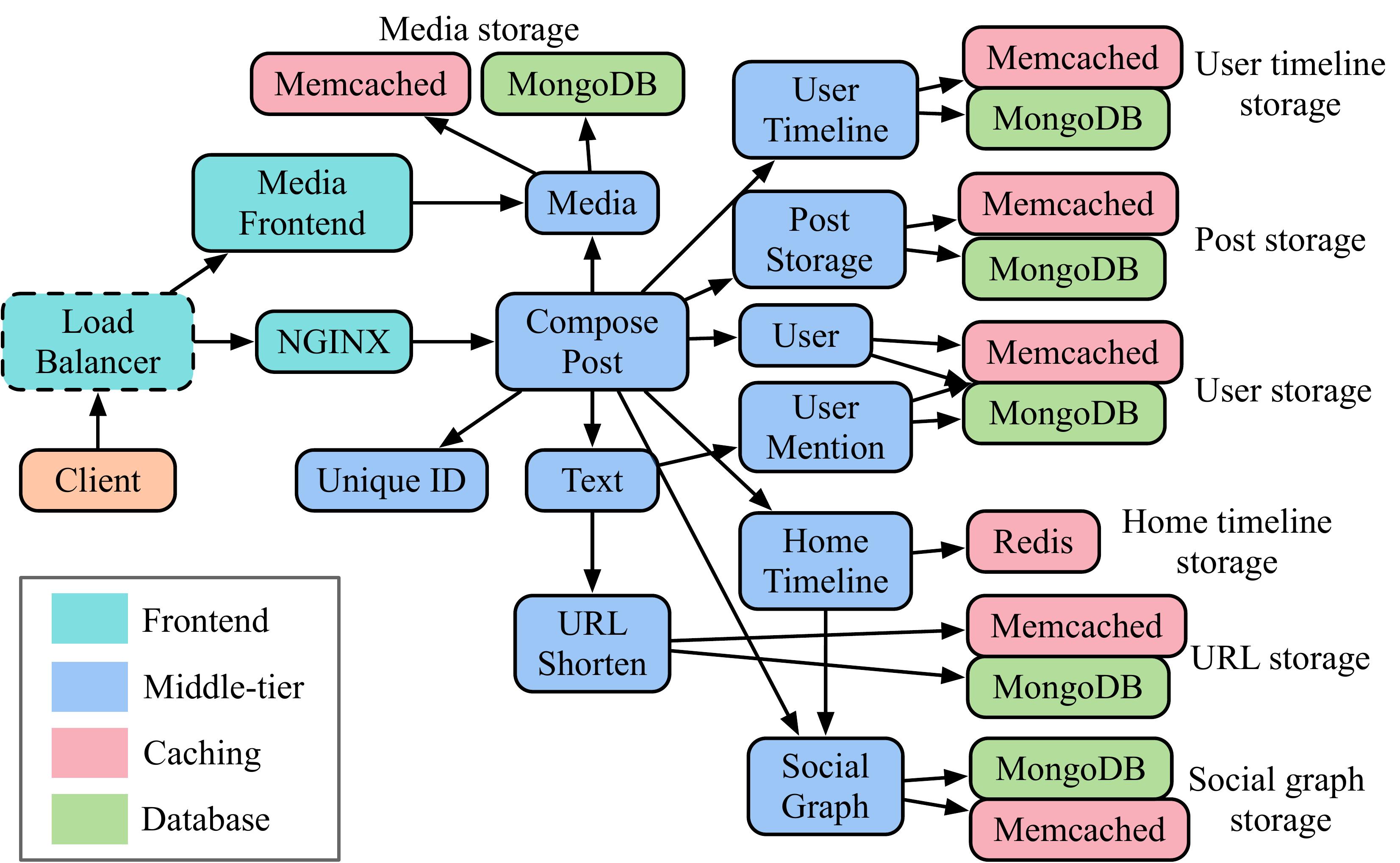
Representative Cloud (Micro)Services
Despite the increasing prevalence of microservices in production clouds, their study in academic environments is hindered by the lack of representative, open-source, end-to-end microservice-based applications. To address this, we developed DeathStarBench, a benchmark suite with several end-to-end applications built with microservices, each representative of a production system using microservices today. These include a social network, a movie reviewing service, an e-commerce site, a secure banking service, a course enrollment system, and a flight reservation service. Each application consists of a few tens of unique microservices in different languages and programming models.
Since its publication, the paper describing DeathStarBench and the system implications of microservices has been recognized with an IEEE Micro Top Pick 2020 award, awarded to the 12 papers from all computer architecture conferences of the year based on contributions and potential for long-term impact. DeathStarBench is open-source software, has over 20,000 unique clones on Github, and is used by tens of research groups and several cloud providers. Not only has this work enabled research projects that would otherwise not have been possible, but it also aids the effort for reproducible research in computer engineering by providing a common reference point studies can compare against.
Despite the value of open-source benchmark suites, there are still cases where having access to the characteristics of actual production services is important. We recently developed Ditto, an application cloning system that faithfully reproduces the performance and resource characteristics of cloud services (monolithic and microservices) without revealing information about the service’s implementation. Ditto is portable across platforms, loads, and deployment configurations, decoupling representative cloud studies from access to production services.
Other Projects
I have also worked on several other projects, including leveraging approximate computing to improve cloud efficiency without degrading performance, designing lightweight containerization mechanisms for cloud-native services, reverse engineering the precise resources an application receives in a public cloud, enabling cloud-native virtualized radio access networks with 5G, managing resources in hybrid private-public clouds and in heterogeneous multicores, using ML to reveal the security vulnerabilities of public cloud multi-tenancy, generating accelerators for reconfigurable hardware, and leveraging data-driven techniques to allocate resources to interactive and batch cloud applications on a reconfigurable processor.